Building the End-to-End Pipeline
Now that the classifier and extractor modules are in place, the final step is to combine them into an end-to-end pipeline. For this, we use LangGraph, a framework designed to build modular, stateful LLM workflows and control their execution across multiple steps.
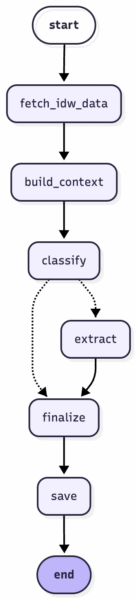
To implement the classifier and extractor module within the pipeline, we used two different LLMs: GPT-5-mini for classification and GPT-5 for extraction. The lighter model is sufficient for binary relevance decisions, while the larger model provides more reliable structured outputs. Both components are wrapped in PydanticAI schemas, which enforce validated output formats and make the pipeline adaptable to alternative LLM providers.
The pipeline starts by retrieving the raw press releases, using the idw API. These inputs include not only the full text of the press release but also metadata such as target audiences, categories, key phrases, and the language.
In the first stage, we use this metadata to perform a lightweight keyword-based pre-filtering step, e.g., by selecting only those press releases that fall into the domains our editors want to monitor. After this initial filtering, the text is converted into a dedicated context format and then processed by the two LLM components. The classifier evaluates whether the press release contains a research project that meets our relevance criteria. Only if the classifier returns a positive result, the extractor runs and returns the project information in a structured form. This makes the extraction step conditional and prevents unnecessary model calls for non-relevant releases. In the final stage, the extracted fields are written to our internal database.
As an example, consider the following idw press release.
After running it through the pipeline via:
graph_agent.graph.invoke({"item_id": 808317})The resulting output is:
{
"id": 808317,
"acronym": "IntelliMan",
"end_date": "2026-03-01",
"funding_programme": "Horizon Europe; Europäische Union",
"funding_total_eur": 6000000,
"project_aims":
" • Entwicklung eines KI-gestützten Manipulationssystems, das durch Interaktion mit Mensch,
Objekten und Umgebung selbstständig neue Fähigkeiten erlernt
und Aufgaben flexibel, leistungsfähig und robust ausführt.
• Gewährleistung sicherer Mensch-Roboter-Interaktion: Sicherheitsanforderungen erlernen
und einhalten sowie Grenzen erkennen, um Vertrauen aufzubauen.
• Erforschung und Demonstration der Handhabung flexibler Objekte in realen Anwendungen
(Oberarm-Prothetik, Küchenaktivitäten, Kabelsatzfertigung, frische Lebensmittel/Logistik).",
"start_date": "2022-09-01",
"title": "IntelliMan (Finanzhilfevereinbarung Nr. 101070136) – AI-Powered Manipulation System for
Advanced Robotic Service, Manufacturing and Prosthetics"
}A daily cronjob triggers the pipeline, ensuring that newly published press releases are processed, and the database is updated on a daily basis. This keeps the stored project information current without requiring any manual intervention.
How Newsrooms Can Use the Output
The information in the database can then be used in several ways. For example, automated Slack notifications can alert specific channels or editors when a potentially relevant research project appears. A dashboard can present all identified projects in a central interface, allowing editors to browse, search, and collaboratively annotate ongoing research topics. Alternatively, the structured data can also feed into topic-monitoring tools that track developments across the research domain over time, helping editors to identify emerging trends.
The pipeline serves as an AI assistant for newsrooms. Running continuously in the background, it monitors newly published press releases, evaluates their relevance, and extracts key project information. This automation removes the need to manually review and evaluate every incoming text, reducing the amount of routine screening work. Importantly, the goal is not to replace human editors. Editorial judgment still remains essential when finally deciding whether a project is genuinely newsworthy or not.
Outlook and Limitations
With this project, we demonstrate that with a manageable amount of development effort, manual workload can be reduced substantially. Similar approaches can be extended to other tasks in newsrooms and science journalism. Examples include automated monitoring of newly published scientific papers and ranking them by potential relevance or novelty, continuous tracking of preprint servers to detect emerging topics, or monitoring various newsletters and blogs for early signals of scientific developments.
Importantly, the current pipeline is not a flawless system. LLM-based classifications and extractions remain imperfect. As shown in Part 2 of this series, our classifier achieves a precision of around 0.75 and a recall of around 0.82. In our use case, the central risk lies in false negatives: press releases that contain potentially relevant research projects but are classified as irrelevant by the model. These missed items represent the main limitation of an automated pre-filtering approach. Fine-tuning, as discussed in Part 2, is one possible way to further improve the classifier performance. A prerequisite for making fine-tuning more effective is extending the training dataset itself. Additional human-labelled examples, particularly for borderline cases, would give the model more reliable signals during training and could improve its ability to distinguish relevant from non-relevant press releases. In principle, a similar approach could also be applied to the extractor module. However, this would require a substantially larger annotation effort, since a gold-standard extraction dataset must contain complete structured fields for many press releases. Creating such a dataset is significantly more time-consuming, which is why we did not pursue this option at this stage.
Eventually, newsrooms therefore need to be aware of the trade-off involved. Automation reduces the time spent on routine screening, but it also introduces the possibility of overlooking projects that might become important later. The challenge is to balance these costs and benefits in a way that meaningfully supports editorial work.